简介
这篇论文是令我印象深刻的几篇关于MIT Cheetah的论文。除此之外还有MIT Cheetah 3提出使用凸优化的方法达到很好的动态控制效果,也算是我正式理解了四足动态控制的关键点。还有一篇就是Mini Cheetah的论文,它提出了低成本的四足机器人方案,在国内可以在1W5左右的成本做出一台四足机器人。
这篇论文第一章是Introduction,介绍了各种四足的控制方法,包括SLIP、WBC、MPC、Nonlinear TO、RL等。
理论与模型定义
第二章开始文章主体部分,从机器人理论建模开始。
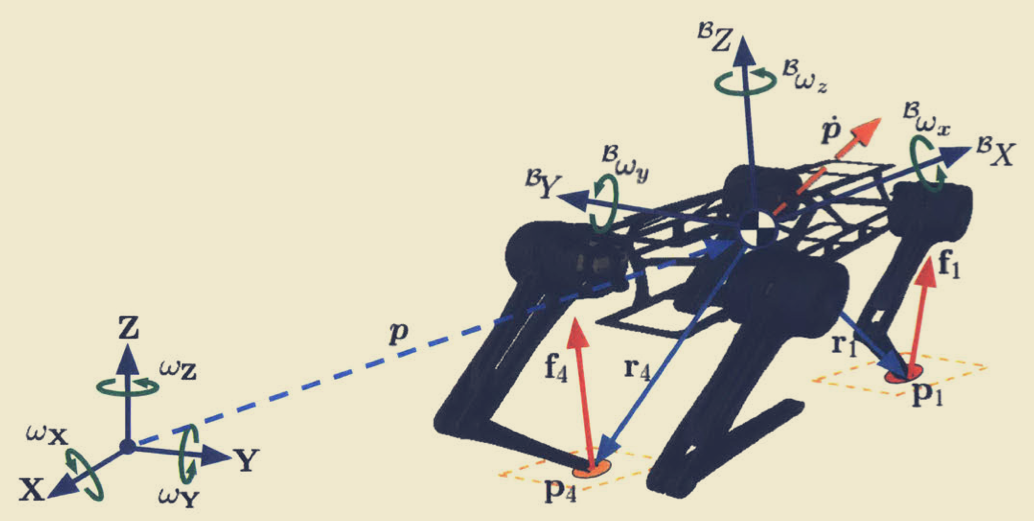
机器人的质心(CoM)表示为:
p=⎣⎢⎡pxpypz⎦⎥⎤
机器人的质心速度表示为:
p˙=⎣⎢⎡px˙py˙pz˙⎦⎥⎤
Bp˙=⎣⎢⎡Bpx˙Bpy˙Bpz˙⎦⎥⎤
p˙=IRBBp˙
对于机器人的身体旋转表示,文章中提到了三种方法,分别是欧拉角、四元数和旋转矩阵。本文中用到的主要与控制相关的方法是欧拉角。
欧拉角表示如下:
Θ=⎣⎢⎡θϕψ⎦⎥⎤
Θ˙=⎣⎢⎡θ˙ϕ˙ψ˙⎦⎥⎤
四元数表示如下:
q˙=⎣⎢⎢⎢⎡qrqiqjqk⎦⎥⎥⎥⎤
旋转矩阵相关的计算如下:
IR˙B=IRB[Bω]×
腿部的关节与足部末端的定义如下:
q˙=⎣⎢⎡qi,Ab/Adqi,hipqi,knee⎦⎥⎤p=⎣⎢⎡pi,xpi,ypi,z⎦⎥⎤
控制架构
控制结构如下图所示,通过手柄输入期望的控制,经过控制器解算后得到机器人的关节控制力矩。其中摆动腿与支撑腿用不同的控制方法,支撑腿用力控制,摆动腿用带补偿的PD控制。
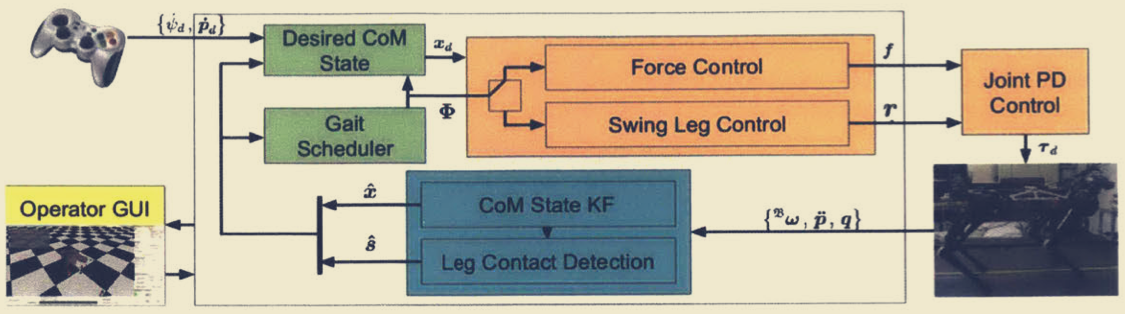
状态估计
MIT这个机器人控制中,很重要的一个部分就是通过机器人的本体传感器,包括关节力矩传感器和IMU,不额外加视觉等传感器,机器人通过估计算法准确的得知机器人当前状态。我记得最早的四足相关的状态估计的论文是ETH出的,使用EKF进行估计,本文进行化简后,可以直接使用Kalman Filter进行状态估计。
状态转移函数如下
p˙=v
v˙=IR˙Bba+g+ωv
p˙i=ω˙pi
在后续文章里,我会补充关于Kalman Filer部分的公式。这里的基本思想就是,依靠支撑腿与IMU结合来估计身体的速度姿态等信息。
腿部控制
- 摆动腿控制
τFF,i=JiTΛi(Bai,ref−J˙ia˙i)+Ciq˙i+Gi
τFB,i=JiT[Kp(Bpi,ref−Bpi)+Kd(Bvi,ref−Bvi)]
τi=τFF,i+τFB,i
- 支撑腿力控制
τi=JiTfi
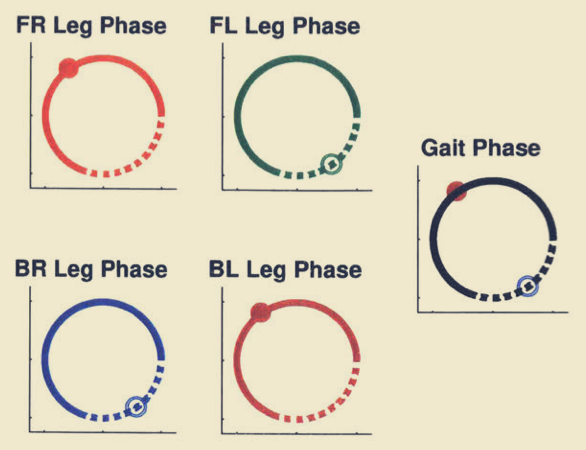
步态规划
这篇论文使用步态相位这种方法来定义步态,通过这种方法可以直接用统一的参数定义比如Trot、Gallop、Walk等步态。论文使用下述参数来计算当前腿的相位或者是状态。这是一个很巧妙的办法,我个人觉得这种方法可以用在强化学习中,作为某种待优化的参数,来使机器人学习到更好的控制策略。
Φi=mod(Tpt−t0,i,1)
足部触地检测
这部分可以参考MIT的论文,Contact Model Fusion for Event-based Locomotion in Unstructred Terrains。理论部分比较多,就不详细展开了。
我个人觉得可以用仿真加随机化获得数据,通过神经网络训练一个检测器出来,结合Sim-To-Real的理念,想办法直接用在实际机器人上。
Regularized Predictive Control
这一章是本文的重点,是控制算法的核心。Regularized Predictive Control在普通MPC算法的基础上,添加人为设计的运动约束,使得机器人具有更好的运动效果。论文中提到:
- The philosophy behind RPC is to use our knowledge of robotic and legged systems to inform the optimization.
MIT还有一篇论文是在MPC的基础上添加Whole Body Control来优化机器人的关节输出,两个方法都有可取之处,不过在我看来,如果四足的运动控制板性能有限,可以考虑选择一个计算量需求小一点的算法,来进行整体的权衡。 (说的就是Up Board)

选择合适的Regular Heuristics Cost Function可以提高优化的结果并提升计算速度,但是若选择了不合适的函数,则可能只能求得局部最优解,甚至无法求解。为了避免手工设计的Heuristics Cost Function具有缺陷,后文作者使用一种基于学习的方法来得到更优的Heuristics Cost Function
MPC Control
这一节主要介绍MPC算法。
为了达到实时的MPC控制,我们需要尽量减少计算量,同时又要保证计算结果的有效性,因此在这里选择了简化模型的方法。
在该模型中,机器人状态定义如下:
x=⎣⎢⎢⎢⎡pΘp˙Θ˙⎦⎥⎥⎥⎤
其中,p 代表机器人位置,Θ代表机器人朝向的欧拉角表示。机器人的控制量为:
u=⎣⎢⎢⎢⎢⎢⎡r1f1...rFfF⎦⎥⎥⎥⎥⎥⎤
由此得到的机器人化简后离散系统的动力学:
xk+1=A(Δtk)xk+B(Δtk)h(xk,uk,Φk)+d(Δtk)
其中:
A(Δtk)=[I606ΔtkI6I6],B(Δtk)=[2Δtk2I−1ΔtkI−1],d(Δtk)=[2Δtk2agΔtkag],ag=[gT 03×1T]T
h(xk,uk,Φk)函数是用于计算足部力与身体力矩的关系矩阵。
在前文提到过,机器人假设欧拉角中roll和pitch角很小,由此简化了动力学模型。MPC就是在前述的动力学方程上加上约束得到的。比如足部力需要满足摩擦角约束,比如足部力必须指向地面之类的,再通过非线性求解器得到输出控制量,进行机器人控制。
Regularized MPC
为了进一步优化MPC表现,作者提出了对常规MPC添加Cost Function的方法来改善结果。而Cost Function是通过学习方法得到的。我个人对这个部分不感兴趣,所以没有深入研究。