Energy Minimization based Deep Reinforcement Learning Policies for Quadrupeds
这篇文章相对其他文章算是简单的一篇,里面用到的很多理论和方法都在以前的论文里出现过。这里只是简单的记录一下。
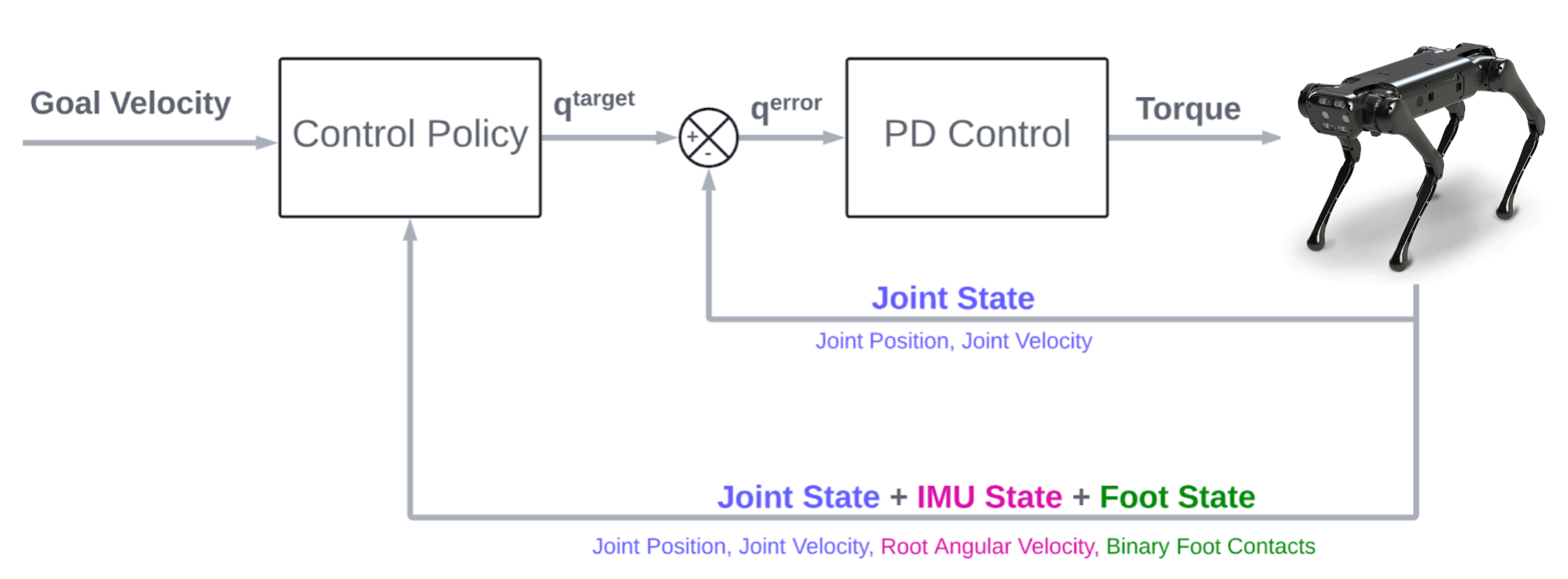
1. RL Framework
- Sim-to-Real: Learning Agile Locomotion For Quadruped Robots: the choice of state space has a direct impact on the sim to real transfer, we note that this can be primarily summarized as the fewer dimensions in the state space the easier it is to do a sim to real transfer as the noise and drift increase with an increase in the number of parameters being included in the state space.
- State Space:
- root angular velocity in the local frame
- joint angles
- joint velocities
- binary foot contacts
- goal velocity
- previous actions
- history of the previous four states
- Action Space: “Learning locomotion skills using DeepRL: does the choice of action space matter? ”: the choice of action space directly effects the learning speed and hence we went ahead with joint angles as the action space representation, further to strongly center all our gait from the neutral standing pose of the robot.
2. Learning Algorithm
- Proximal Policy Optimization Algorithm
- We use a Multi Layered Perceptron architecture with 2 hidden layers of size 256 units each and ReLU activation to represent both the actor and critic networks.
- Hyper Parameters:
- Parallel Instances: 32
- Minibatch size: 512
- Evaluation freq: 25
- Adam learning rate: 1e-4
- Adam epsilon: 1e-5
- Generalized advantage estimate discount: 0.95
- Gamma: 0.99
- Anneal rate for standard deviation: 1.0
- Clipping parameter for PPO surrogate loss: 0.2
- Epochs: 3
- Max episode horizon: 400
- Reward Function
3. Curriculum Learning
- This approach is based on the idea that starting with simpler tasks and gradually increasing the complexity can help the agent learn more efficiently.
- There are two ways in which curriculum learning is usually implemented. One is to use a pre-defined set of tasks or environments that are ordered by increasing difficulty. The agent is trained on these tasks in a specific order, with the difficulty of the tasks increasing as the agent progresses through the curriculum. Another approach is to use a dynamic curriculum, where the difficulty of the tasks is adjusted based on the agent’s performance.
4. Sim-To-Real
- We employ a mix of domain randomization and system identification for sim-to-real transfer.