本篇论文在RMA的基础上进行改进,提出了一种更加鲁棒的RL算法,在训练时使用了NVIDIA的Isaac Gym仿真器,可以在很短的时间内完成训练,并直接部署到实际机器人上。这篇文章大体的思想和RMA很像,但是它使用另外一种方法进行隐式的系统参数辨识,从而达到鲁棒的控制效果。训练的Policy结构如下图所示。
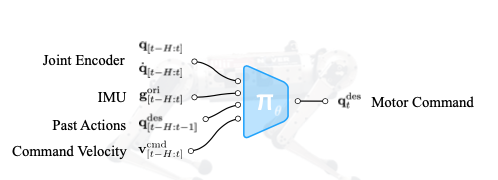
本文使用的Teacher-Student的训练方法来包含具有特权的仿真环境参数。老师的训练方法与RMA基本一样,不过也引入的对特权参数的神经网络编码器,学生通过类似Adapter Module的神经网络来拟合对特权参数的预测,并且不断模仿老师的动作。当Adapter Module已经可以很好的拟合特权参数时,就停止对Adapter Module的训练,并直接使用编码后的特权参数作为老师和学生的输入。
训练的Policy是为了达到很好的速度追踪效果(对于手动控制机器人来说具有类似的特性),论文中采用了随机方法生成速度控制量。为了提高训练效果,本文也采用了逐渐增加难度的方法来逐渐增强Policy的能力。
总体来说,我感觉本文与RMA很相似,可能可以算作一类控制思想。