这篇论文是关于强化控制的论文,实现的RMA算法可以在仿真环境训练完后,直接部署到机器人实体上,具有不错的控制效果。
RMA由两个部分组成,分别是Base Pilocy 和Adaption Module 构成。
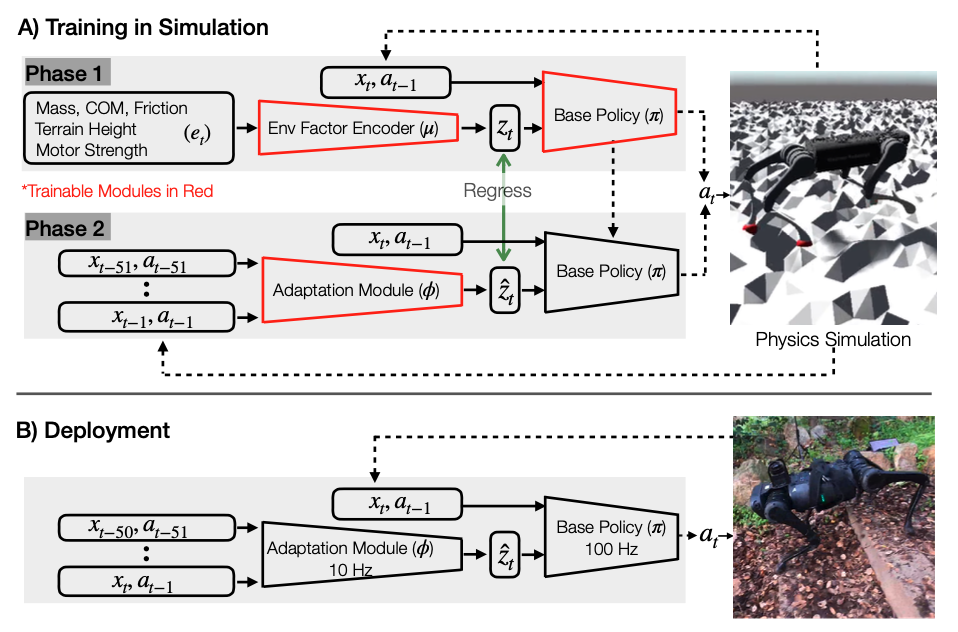
在训练过程中,RMA由两个阶段组成,在第一个阶段,Base Policy 将当前状态 ,上一个动作 ,和经过编码后的具有特权的环境参数(Privileged environmental factors ) 作为训练输入,使用model-free的强化学习算法在仿真中学习。在第二个阶段,Adaption Module 用过去的状态与动作结合监督学习去预测 。为了保证数据的有效性,给 训练用的数据是经过一定训练后采集的on-policy数据。
在部署(Deployment)阶段,Adaption Module 使用10Hz的频率进行状态预测,Base Pilocy 通过100Hz的频率来产生控制数据。输出的控制 是关节位置,通过一个简单的PD控制器转化到关节控制力矩。由于Adaption Module的运行频率较低,Base Pilocy使用最新产生的预测值来产生控制量。论文中说,这种异步控制是由仿真环境迁移到实际机器人的关键。
论文中还提到了一些其他细节,比如为了避免学习的Policy直接摆烂,刚开始的任务难度要低一点,同时惩罚的量要小一点。随着训练的Policy能力逐渐增强,我们可以不断提高难度和加大惩罚,这样可以提高训练的效率。为了使算法更加鲁棒,采用了Domain Randomization的技巧等。
其他具体内容请阅读论文,我也是刚开始学习相关知识,文中的各种疏漏也请谅解。